Ever since we started Phage Directory, we’ve heard many times from many people that the phage field “needs a database for phages.” Since then there have been many databases, from the rudimentary “host index” here on Phage Directory, to the Viral Host Range Database by Pasteur or the International Phage Therapy Database by Shawna McCallin. There’s also of course the original Actinobacteriophage-centric PhagesDB, run by the Hatfull lab. Many groups like ATCC and NCTC showcase their own phages and hosts, and DSMZ is rolling out their database.
Even with these database projects, there’s a distinct feeling that there’s still something missing. Turns out, we don’t really need a database; what we really want is an easy way of looking up:
- What do we know about a phage, is it what we think it is, and is it pure?
- Where did a phage come from? Where did it go? And what’s been done with it?
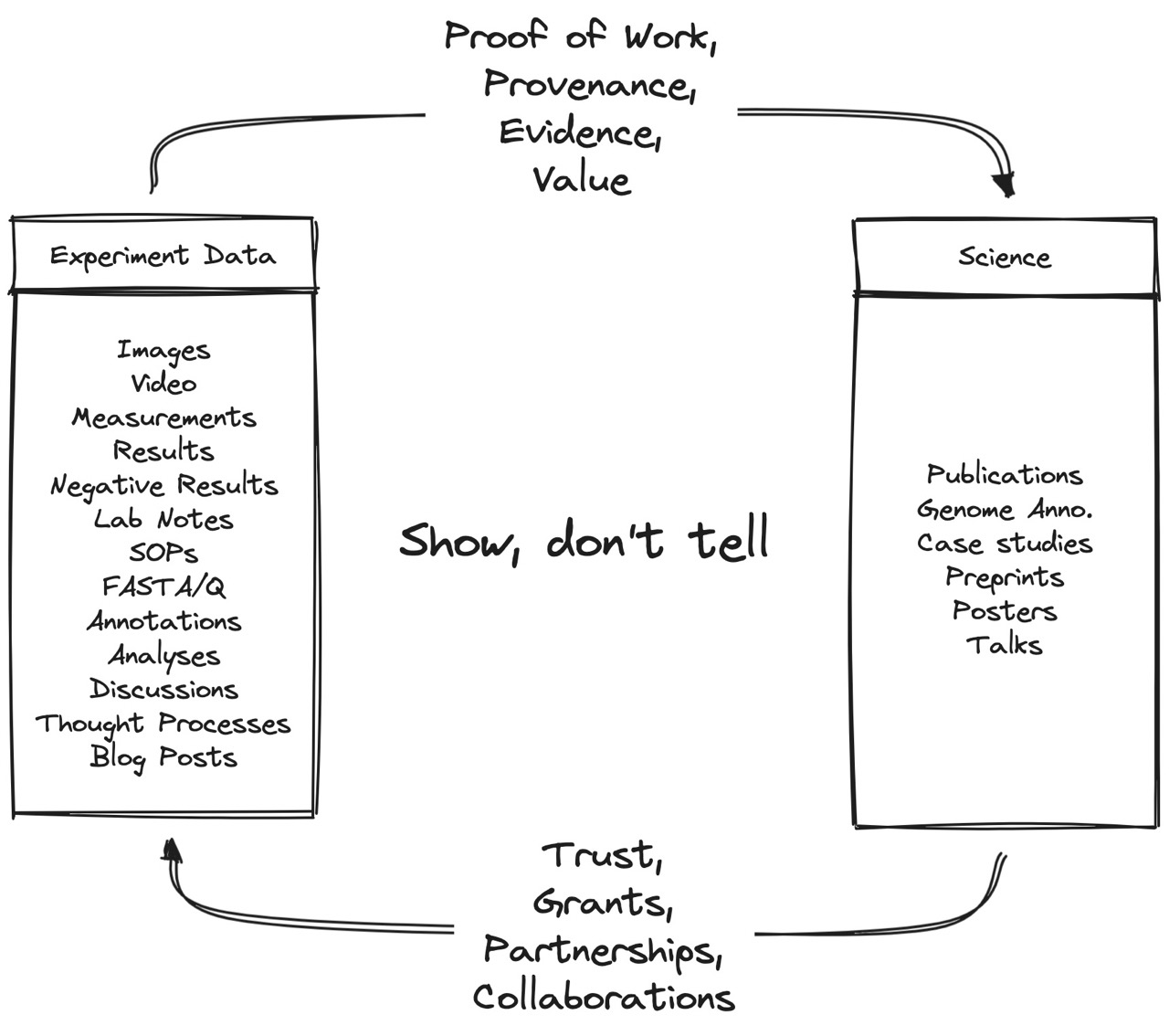
Fig 1. Show, don’t tell. Experiments generate data, which backs up the science with evidence. Good science backed up by evidence leads to higher trust, more grants, partnerships, and better collaborations. Inspired by @jackbutcher’s “Sell your Sawdust” thread.
When we send or receive phages, we want to trust that a tube of phage is exactly what the label says it is. Re-checking every phage sent between labs is time-consuming and uneconomical for large phage banks.
As the phage field moves towards producing GMP(-like) phages, both lab processes and assay data need to be consistently and meticulously documented. Standard Operating Procedures (SOPs) need to define data collection requirements, which need to be stored.
The more data we’re able to gather from our experiments, assays, and bioinformatics pipelines, the higher our confidence will be that the phage is actually in that tube, and that it’s pure.
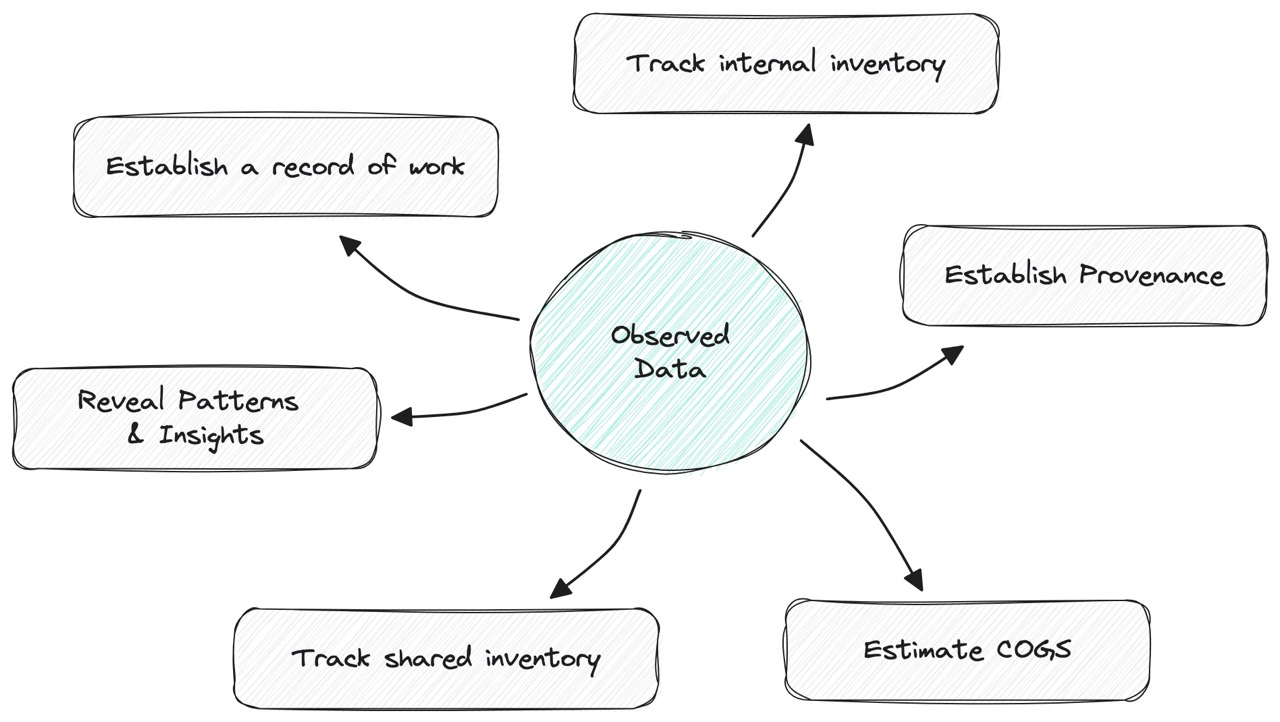
Fig 2. Observed data collected from experiments helps us derive understanding about our phages. Isolation data tells us where it came from, and accession data tells us where it’s stored. Plaque assay data tells us its host range. This all “proves” where the phage came from, and what it’s like to work with it. It even helps us estimate “COGS,” which in this case is how much effort, materials, and lab time it took to produce a phage.
Collectively, we should aim for a creating a catalogue, or “Pokédex,” of phages. The catalogue should provide enough information for another lab to make their independent assessments about the quality or usefulness of a phage, before they receive it. By sharing our SOPs, wet lab data (like plaque assays) and bioinformatics data (like FASTQ, Genbank and Snakemake/Nextflow configurations), we’ll get one step closer to establishing “Material Safety Data Sheets” for phages.

Fig 3. An illustration of a “Pokédex-like” phage entry, where attributes about a phage should be calculated from its assay results and genomic data. Lab results should be auditable, and genome sequences and config files should be shareable.
There’s a vast amount of data to be collected and shared about a phage. We could add all the DOIs of every paper and case report it’s ever been published in. We could share relevant, de-identified immune response data of every patient that’s been treated with it. We could share plaque assays and OD values for every phage/host interaction. We could share the raw FASTA file and Nextflow pipeline for anyone to run. The list goes on.
Even though the data system needs to support every possible type of characterization, it’s up to the lab to publicize their SOPs, perform the work and catalogue the data accordingly. It’s also up to consortiums like Phages for Global Health to publish minimum criteria for both research and therapy use, and for receiving phage labs to perform their due diligence.
Eventually, labs and consortiums should establish SOP and data requirements for both minimally-acceptable phages as well as higher levels of grading with more stringent criteria for each grade.
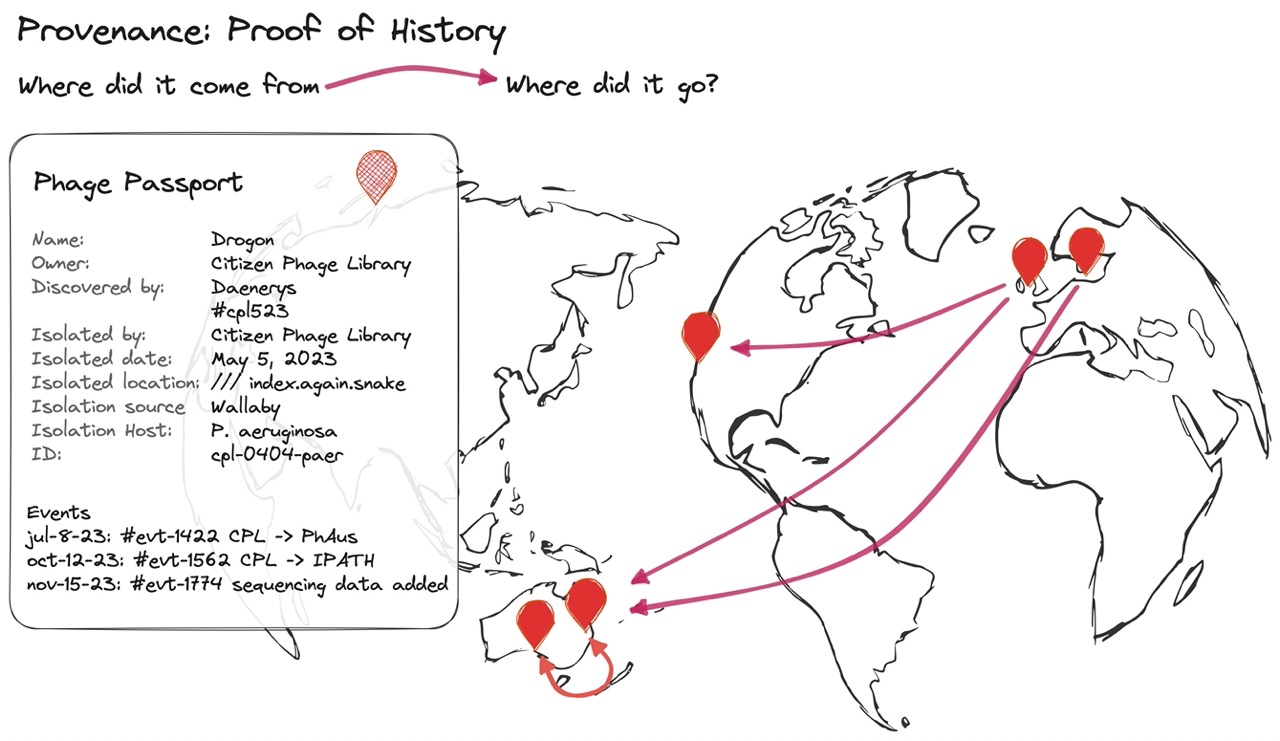
Fig 4. “Provenance” is our ability to prove where a phage came from. We can think about it like a combination of a Birth Certificate, a CV, and Passport of everything it’s ever done, and everywhere it’s ever been sent. As each lab receives, characterizes, and uses the phage, they’ll add to the phage’s CV by contributing data to it.
The more data labs publish about their phages, the easier they can plant their flags and stake their claims that they found, isolated, and characterized the phage. When labs share a published phage with other labs, other labs can then add more data like new patient treatments, expanded host range, production quirks, etc. to the phage’s history. This adds to the provenance and history of the phage. As a phage becomes more characterized and treats more patients, its list of accomplishments will grow, and the phage will be more provably useful, and valuable to clinicians.
As labs contribute data to a phage’s history, they also become a part of the phage’s provenance and history. At Phage Australia, we’re working on a transfer agreement framework where royalties from phage licensing deals will be fairly distributed to data providers for each phage.
What if another lab isolates a phage that looks and behaves similarly in the lab? We can consider it a twin or “doppelgänger” with a different history and provenance. Even if we think it’s exactly the same, we would still need to prove that it functions identically, through further characterization and genome analysis. In essence, we’ll need the data to confirm if two “identical” phages are actually identical in vitro or in vivo.
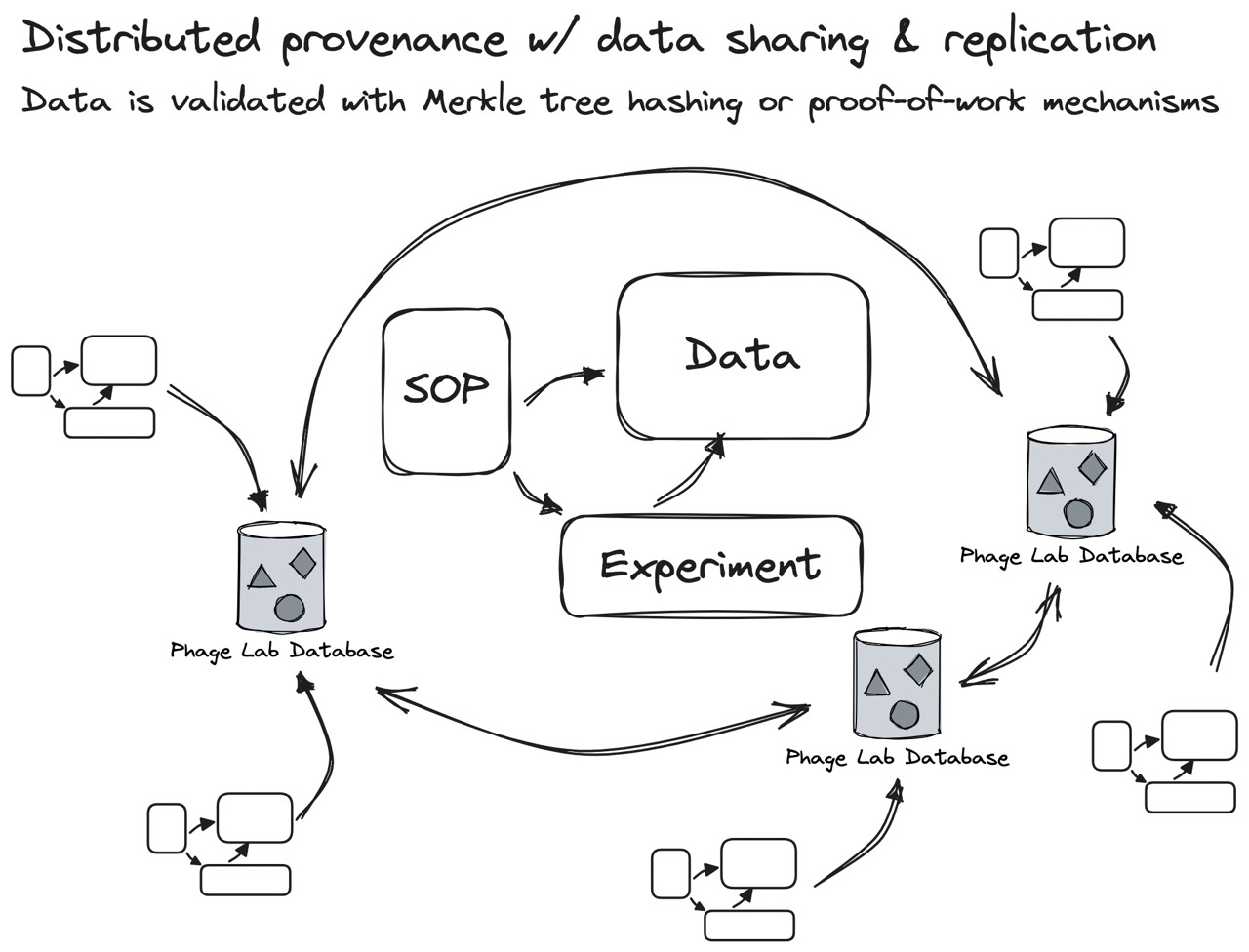
Fig 5. Data should be generated from experiment results that follow published SOPs. Instead of using a single database, the data system should allow labs to run their own replicated nodes within a network of “federated” databases (similar to Mastodon). This gives each lab the freedom to control what data is shared, and what data stays private within the lab. To comply with GMP and lab audits, the phage field could eventually borrow cryptographic ideas like “Merkle tree hashing” or “ZK rollups” to support both verifiable and anonymous data.
There’s no such thing as a “static phage” — they genetically drift or change as they’re sent and used by other labs. When labs receive, work with, and send their phages, they would need to add their own experiment data to the phage’s history. This is especially necessary if labs decide to train or engineer the phages in any way.
As phages are sent back and forth between labs, phenotypic and genotypic variations will arise. This can all be tracked throughout the history of a phage’s ancestry, as “siblings, cousins, and children” with different in vitro and in vivo characteristics will eventually emerge.
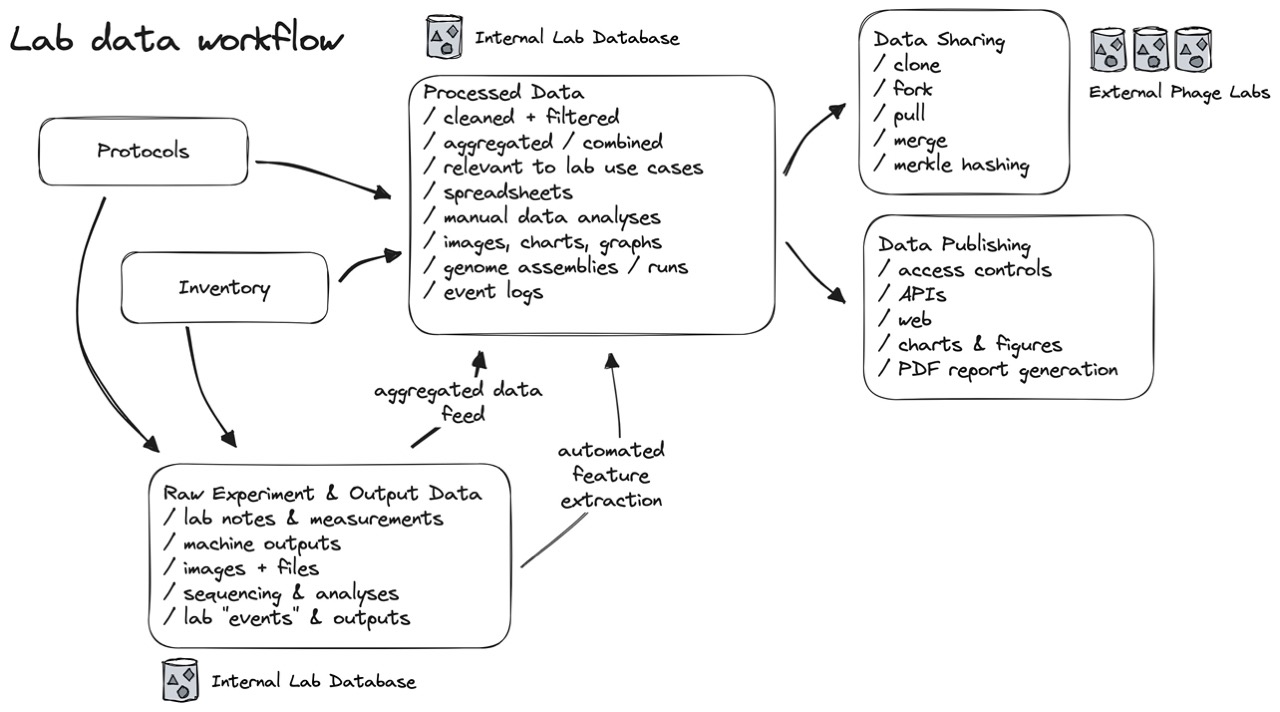
Fig 6. Experiment, assay, and machine data are collected as event logs, and then aggregated and indexed into the “real” database. This lets us treat anything we know about our biobank as a “snapshot” of knowledge in time, similar to how a bank can calculate the balance of an account at any point in time. Using an aggregator also lets us selectively filter and share only relevant information with other labs and with the public, without worrying about airing all our dirty laundry.
Our data is only as good as the lab work that generates the data. This is why sharing protocols — and having strict data requirements — is so important. We need to know which groups report temperature as Celsius, and which as Fahrenheit. We should also acknowledge that our protocols will always improve, which means our data will always improve. This means that we need to always know which SOPs generated which data. As methods and pipelines improve, this would also allow us to deprecate older results created with older, out-of-date methods.
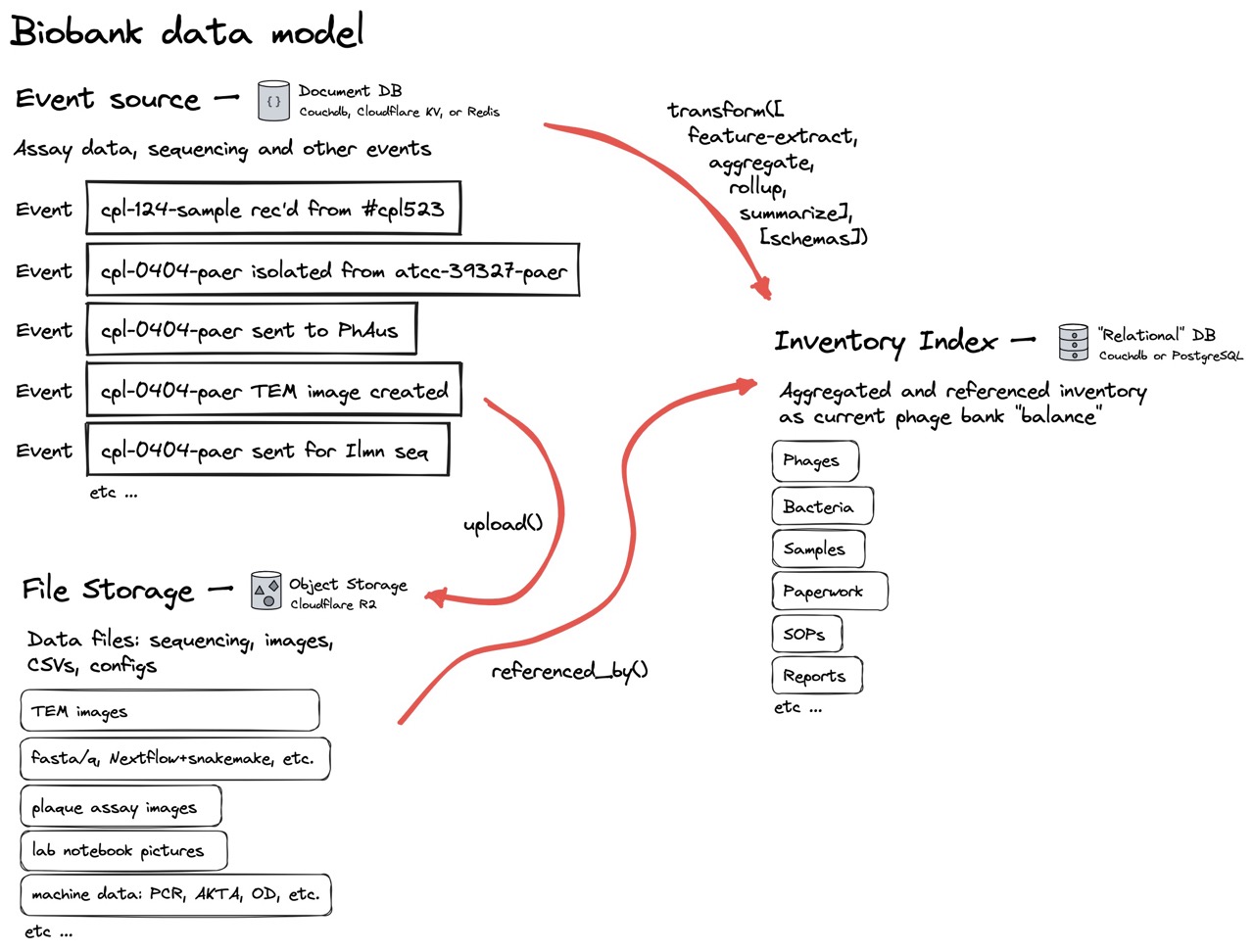
Fig 7. In this simple data model, all lab results data is collected as event logs in the “Event source” database. All files, like CSVs and FASTA files are uploaded to the file storage database. We can then combine and calculate information about our phages and bacteria directly from all the lab results and uploaded files, into an “Inventory Index” which, like a bank account balance, is always kept up to date. Any additions, edits, or corrections are added as new “events,” which are then recalculated into the Inventory Index. Such a system allows a lab’s data to be auditable at any point in time.
When our proposed data system collects results from raw experiments, data from machines, and genomics analyses, the data will come in many forms, from free text, to CSV, images, and other files. The system should ideally be able to store all of these use cases. Any piece of recorded text or uploaded file should be recorded as an “event,” and any files should be automatically uploaded to an object storage service like AWS S3 (similarly to Notion or Airtable).
The biggest difference between this system and something like Notion or Airtable, is that this system doesn’t let users directly touch the database. Instead, it “calculates” or “derives” all information from the event log.
This kind of separation prevents us from overwriting previous details about phages, and keeps our inventory up to date at all times. The data model can be thought of as a combination of Notion, Airtable, and a transaction system like bank accounts.
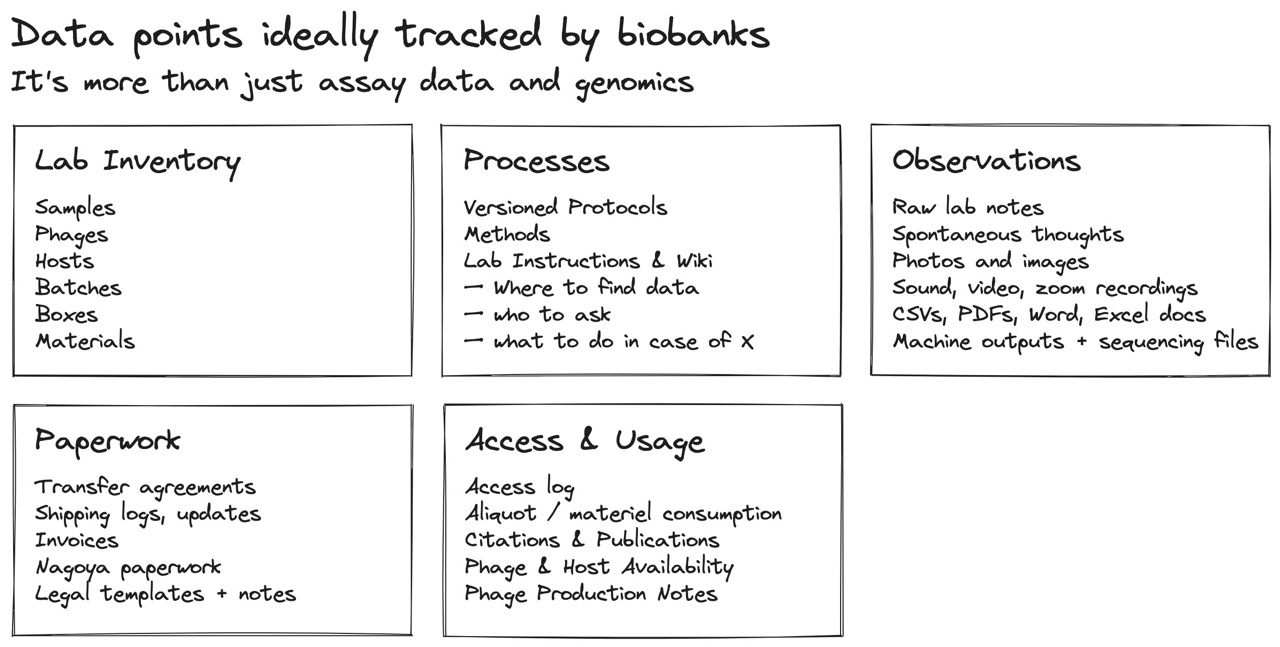
Fig 8. Biobanks will need to track more than just assay results and genomics outputs. Most LIMS and ELNs try to track a subset of lab inventory or notes, but are either too expensive or become too constrained. Both lab inventory and lab notes need to be treated as two sides of the same coin, as they both contribute to the “current state of a lab and its experiments.” To support phage exchanges, labs will also need to exchange any usage, handling, and production instructions for phages, as well as all the paperwork and transfer agreements that come with the territory.
A lab collects much more than just experiment results and FASTQ files. Other attributes that need to be aggregated for a phage includes things like transfer agreements (which are inherited when a lab receives a phage then passes it on), safety and production notes, host characteristics, and various “gotchas” that come with working with a specific phage or production host. Any of these notes should ideally be shared along with a phage. Any quirks about using or handling the phage that other labs learn along the way should be added to the phage’s history.
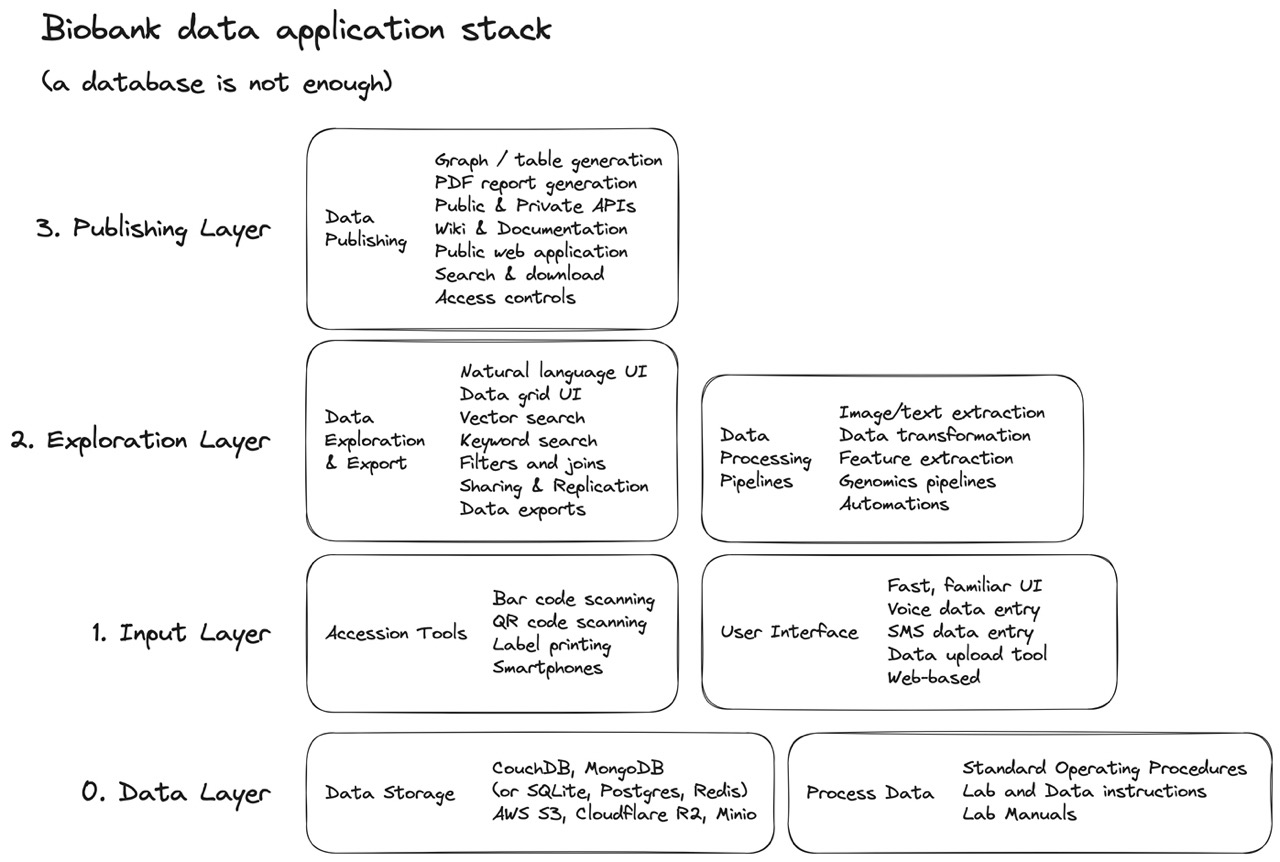
Fig 9. We don’t want really just “want a biobank database.” What we want is a full-stack data application that securely tracks and uploads any data or file object, helps us easily add new data like lab and inventory notes, provides us with semantic and keyword query capabilities, lets us filter, combine, and download (only) relevant data, and gives us fine-grained controls over how we can publish and share the data — either with the web, with collaborators, or as a PDF or graph, figure, or table.
We don’t actually want another “phage database” or a “LIMS” or an “ELN.”
We just want something that works — that can easily store, explore, and share our thoughts and data. We want something like Notion/Airtable/Excel/Dropbox, for the lab. And open source. And affordable.
We just want a system that can help us answer:
- What do we know about a phage, is it what we think it is, and is it pure?
- Where did a phage come from? Where did it go? And what’s been done with it?
But that’s also auditable, shareable, and collaborative.
For the rest of the year, we’ll dive deep into each layer of the biobank data application stack, build some prototypes, and discuss how to make each layer a reality — and progressively build and release each layer as open source code.
Further reading & acknowledgments
Thanks to Ben Temperton and Jon Iredell for all the brainstorming and brainstorming. Illustrations were created in excalidraw.com.
How to make your scientific data accessible, discoverable and useful [Nature]
To share is to be a scientist [Nature]
Data-Oriented Design [Richard Fabian]
Sell your sawdust (Share your work in progress; prove yourself in public) [Jack Butcher]
Immutable history / event sourcing [couchdb.org]